
This post has been first published as part of my participation in the Web Performance Calendar 2023. This version contains small updates.
Server-rendered Redux apps commonly have to transfer the store state from the server to the client. Transferring large states can be slow, so in 2019, Henrik Joretag benchmarked three approaches to figure out the most performant way:
// "Plain object":
window.__STATE__ = {"foo":"bar"}
// "Invalid mime type":
<script type="mime/invalid" id="myState">{"foo":"bar"}</script>
window.__STATE__ = JSON.parse(window.myState.innerHTML)
// "Just parse":
window.__STATE__ = JSON.parse("{\"foo\":\"bar\"}")Back then, the “just parse” approach was the fastest one, much faster than “invalid mime” and “plain obj”.
The V8 team also compared JSON.parse to the plain object notation and made it faster in 2019, too (and they talked about it again and again – and again). All this emphasis on JSON.parse perfectly aligns to Henrik’s findings.
However, in 2023, things have changed. Maybe not in the way you’d expect. Let’s dive in 🕵️.
― there will also be a small challenge (“Advent of Code WebPerf”) 👀 ―
Table of contents
Open Table of contents
Following the performance trails 👣
Back then, Henrik’s experiment showed the following results:
Avg Perf Score Avg. TTI
"plain obj": 87.2 4.04 s
"invalid mime": 90.8 4.02 s
"just parse": 95.2 3.30 sAs we can see, the “invalid mime” approach was equally slow to the “plain obj” approach. Only the “just parse” approach showed much faster Time-To-Interactive (TTI).
However, Lighthouse 10 removed TTI as a metric due to it’s unreliability and the fact it’s prone to outliers1. This already gives us a hint that performance might change over time. What appeared to be the best back then, might perform different today.
Let’s take a look at how the “invalid mime” would be used in an HTML document:
<script type="mime/invalid" id="myState">{"foo":"bar"}</script>
<script>window.__STATE__ = JSON.parse(window.myState.innerHTML)</script>We pass the state content as JSON string in a script tag with the type “mime/invalid”, which is certainly not any of JavaScript’s MIME types. This means, browsers won’t hand it over to any JavaScript engine, so nothing will execute it.
So what exactly made it so much slower even though it also uses JSON.parse – could it be the innerHTML usage? 🤔
Microbenchmarks: Reading from DOM, fast ⏱
Jason Miller (the author of Preact) once tweeted that using textContent is faster than innerHTML for setting content (benchmark).
However, reading and setting might be different, so let’s create some tests to validate the hypothesis.
ℹ️️
Microbenchmarks don’t always paint the full picture. More on that topic later.
To get a fairly good result, we have to make sure our input is big enough (Henrik’s redux state was around 160 kB). A simple, but big object will do the trick for now (for (let i = 0; i < 10000; ++i) obj[i] = i). Let’s see how they compare:
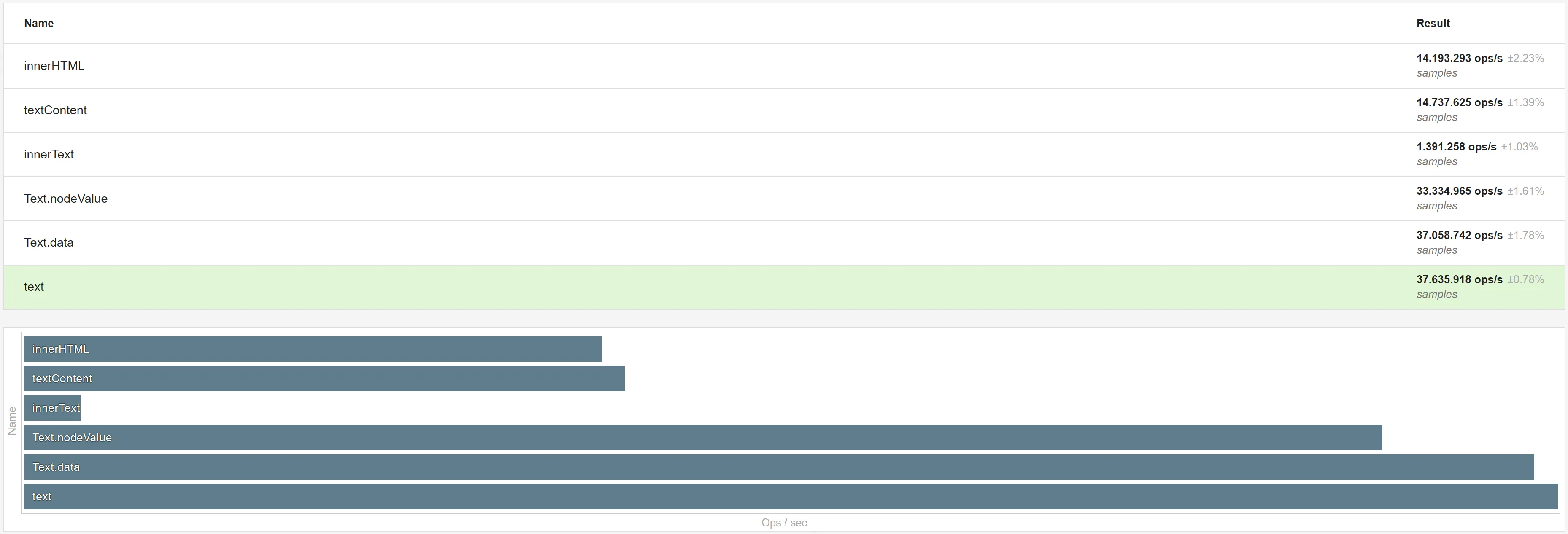
.text, which is the shortest option.So swapping implementation to JSON.parse(window.myState.text) must be the way to go and make the “invalid mime” approach win by a lot, right?
Not so fast.
Currently we’re benchmarking only the inner-most statement: text vs innerHTML.
What we’re actually trying to measure is: What results in the fastest assignment of the state data?
To measure that, let’s wrap each call in JSON.parse and use a real JSON string (~60 kB):
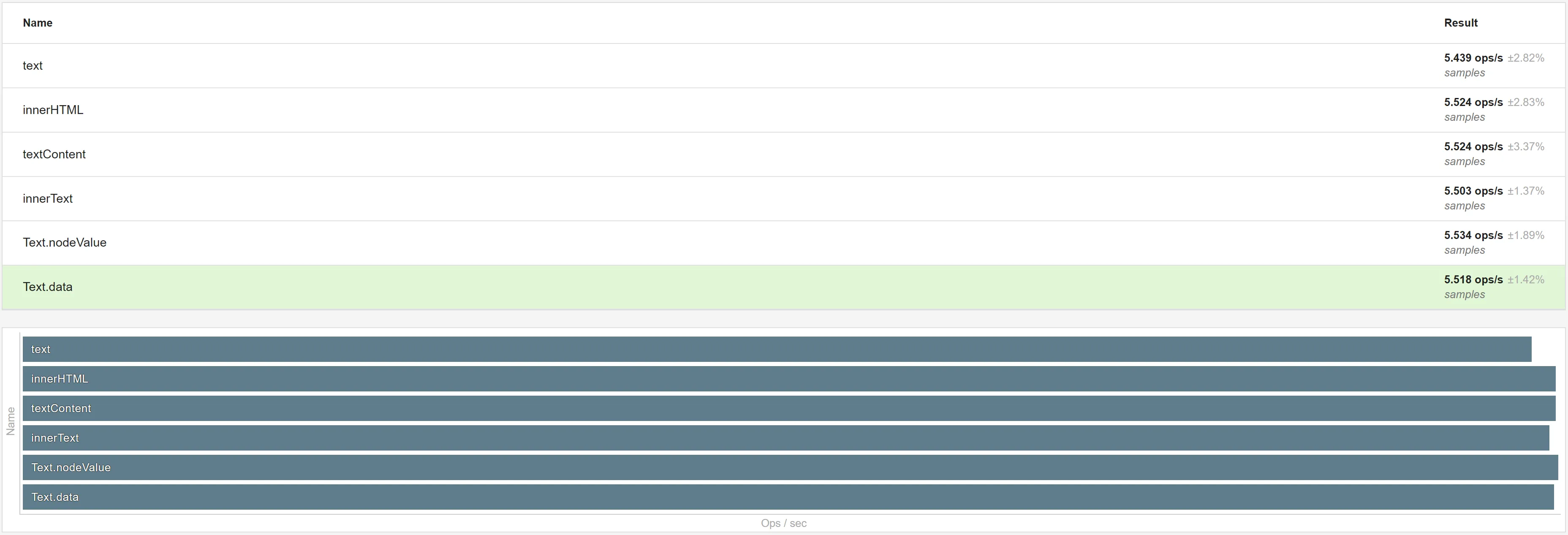
Wooops! Pretty much all are similar now. What the heck? 🧐
If all are equal after adding JSON.parse, we can deduce that JSON.parse is the bottleneck and it does not matter too much how we read from the fake script node.
Now that we know parsing has the most impact on runtime performance, a second question arises:
If the “just parse” approach uses JSON.parse and the “invalid mime” approach also uses JSON.parse, why was the “invalid mime” approach so much slower than the “just parse” one?
Page Benchmarks: Measuring Impact 🎯
The most obvious difference between the “invalid mime” and “just parse” approach is that the latter only uses one script tag. We unfortunately don’t have Henrik’s code from back then, and microbenchmarks can’t really tell us why two DOM nodes might be slower than one DOM node. So let’s figure out a new way to get a good comparison.
On small pages, where there is not too much work for the HTML parser, measuring the impact is harder and does not reflect real-world usage. So we want a DOM-node heavy page that really taxes the main thread during initial load. Sounds like we need a long spec for that - literally. The MIME sniffing spec perfectly fits this use-case. Combined with throttling the CPU using DevTools, we get a somewhat representative picture of a slow website on our fast development devices.
To measure how the “just parse” and the “invalid mime” approach stack up, we’ll use a simple script placed right before </body>:
<script>before = performance.now(); performance.mark("start")</script>
… the approach we're benchmarking …
<script>performance.measure("end", "start"); console.log(performance.now() - before)</script>The “start” and “end” marks show up in the Performance Tab of DevTools, which will help us investigate further.
performance.now()
By refreshing the page multiple times, I arrived at the following values in average (on the machines I’ve tested with):
“just parse” test page · “invalid mime” test page · “plain obj” test page
While Chromium/Edge DevTools allowed me to simulate a 6x CPU slowdown, Firefox & Safari unfortunately don’t have that option2. Also, performance.measure is not as precise as Chromium in those browsers, which means we can not really compare.
➡️ All in all, the “invalid mime” still seems to be the fastest – with up to 50% higher performance 🚀.
Measuring doesn’t tell us the ‘why’ though, so… here’s your part:
DevTools: Your Advent of WebPerf Challenge 🎄
Try to find the cause yourself first. Play around with the following two traces from DevTools using either of the links:
- DevTools Timeline Viewer (chromedevtools.github.io) – top: “just parse”, bottom: “invalid mime”
- In case you prefer to open the traces in single tabs:
Can you spot any differences? If so, what do you think is the cause?
💡️
Need a hint? Look for the yellow 🟨 “end” event in the “Timings” row. You’ll find the answer in the next chapter.
― Did you like the challenge 👍👎? I’d appreciate hearing your opinion on X @kurtextrem or Mastodon for possibly future challenges ―
Performance Deep Dive: Compiling A New Winner 🏆
First, to make “behind-the-scenes” tasks (e.g. tasks from the JavaScript engine) visible, I’ve also turned on the following DevTools experiments:
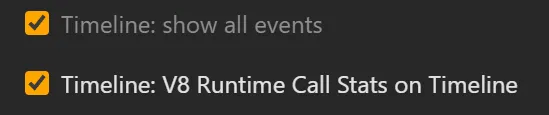
They are not not needed to find the cause, but help explain what’s going on as part of this article.
The following screenshot shows the important bits side-by-side:
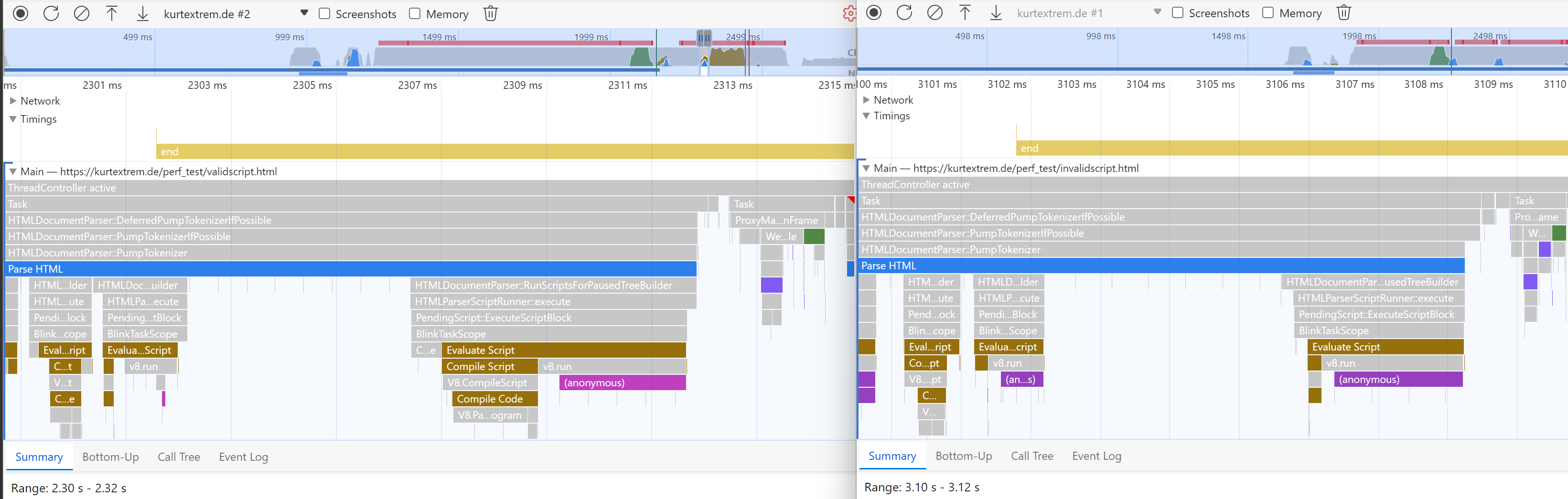
Was your conclusion “the difference seems to be the longer compile script task”? Correct! ✅
If not, don’t worry, the explanation is coming right up 👇
Things that shouldn’t live rent free in your JavaScript
Here’s what’s going on. Take a look at the screenshot again, this time I’ve marked the important differences with a blue box:
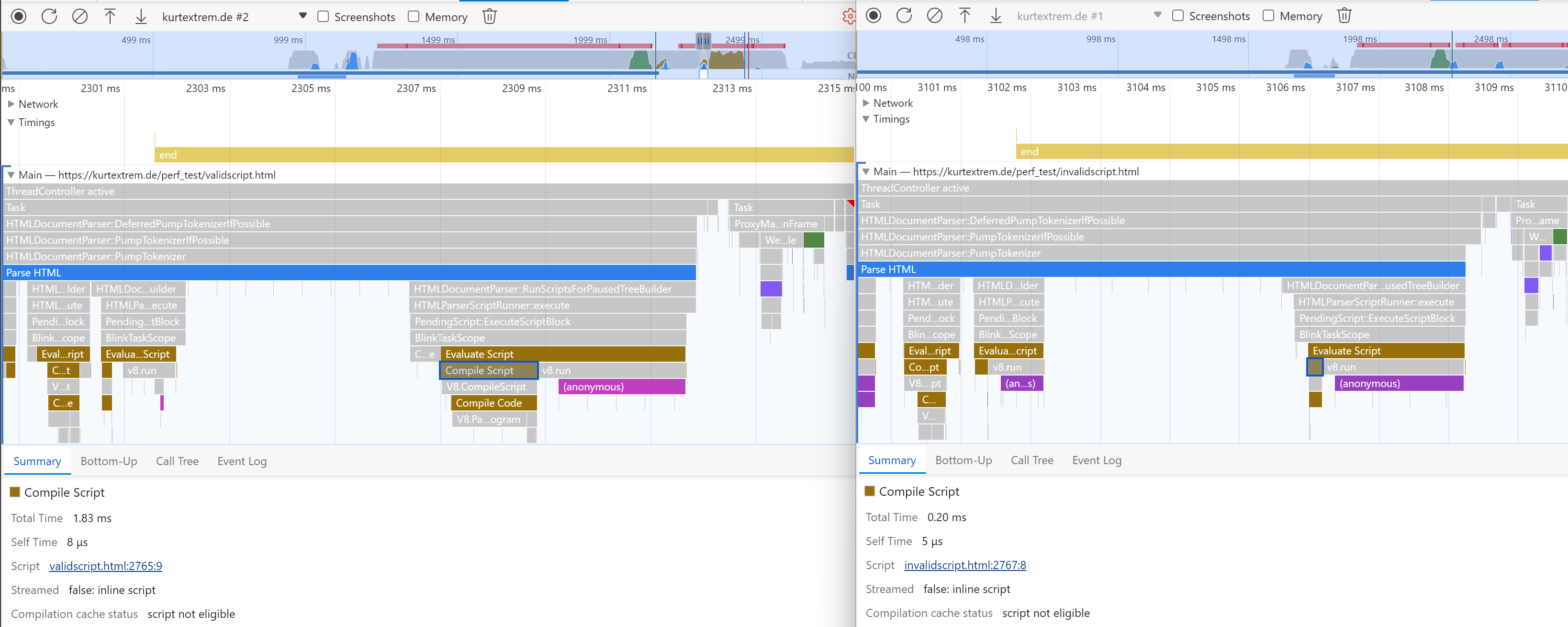
As you can see, there is a major difference in how long V8 takes to compile the script.
Both have the “evaluate script” task (brown/yellow), followed by “compile script” and “compile code”.
However, the “just parse” approach (left) is slower because it spends much more time doing the latter. The reason is the huge string inside the JSON.parse function:
window.__STATE__ = JSON.parse("{\"foo\":\"bar\",\"baz\":\"bar\", [...60 more KB...]}")As this string is a part of the JavaScript code, it has to be parsed and compiled by V8 before execution. Comparing that to the “invalid mime” approach (right):
window.__STATE__ = JSON.parse(window.myState.text)Where the huge string is avoided inside the JavaScript code itself, which means V8 has much less to parse. The string we need is read from the DOM node instead.
We can also see there is no gray HTMLDocumentParser task associated with the invalid-MIME script node, so the HTML parser also does nothing special with it. From that we can conclude that “plain object” and “just parse” measure how fast the JavaScript engine’s parser is, while “invalid MIME” measures how fast the HTML parser is.
Additionally, the “invalid mime” approach produces a 6% smaller string as it avoids double escaping. You still need carefully escape closing HTML tags (</script>)3, by using modules like jsesc or devalue.
All of those gains matter not only for performance, but also for inclusivity, as there are multiple regions of the world where your customers use slow Android devices with specs similar to devices from 2017 as daily device.
ℹ️️
Large JSON strings are not the only compilation bottleneck. If you find that topic interesting, I’ve written a deep-dive blog post on parsing & compilation, where I look at another common source of bad compilation times: SVGs in bundles – and how to optimize them.
💡️
Perf Tip:
Move the parsing cost (what we see as “evaluate script”) to a later point during the page loading phase,
e.g. to right before the hydration, or to an idle phase using requestIdleCallback, or like the framework Qwik right before/on user interaction. That way we make sure the browser only does work that is actually needed and we don’t tax the main thread unnecesarily.
Might matter to you: Freeing-up Memory
One more thing: If we’re in a memory-constrained environment, we could remove the fake-script DOM node afterwards to allow rendering engines to free up memory in the next garbage collection run:
<script>
window.__STATE__ = JSON.parse(window.myState.text)
// remove fake script tag:
window.myState.remove()
</script>Be careful where you remove it from, because removing DOM nodes from <body> could cause other side-effects which are bad for performance. In the case of the “MIME sniffing” test page, it causes a very long “recalculate style” task (test page).
You can avoid this by putting the script tag into a <div hidden> node (test page).
Check the trace comparison, where the “recalculate style” task comes right after the “end” event in the upper trace – whereas the bottom one with the hidden div has a much smaller task after the “DCL” event.
💡️
Using a seperate DOM node instead of adding or removing direct children of <body> also makes sense for things like tooltips as explained here by Atif Afzal. In general, removing and adding DOM nodes always comes with some cost.
Wrap Up
Phew. What a journey. To summarize, the “invalid mime” approach wins:
<script type="mime/invalid" id="myState">{"foo":"bar"}</script>
window.__STATE__ = JSON.parse(window.myState.text)It is up to up to 50% faster during runtime and up to 6% smaller3, which makes it the nowadays best approach to get data from the server to the browser.
Coming back to the big picture. We went an extra mile to check the performance of the different approaches. Was it worth? In my humble opinion, yes. We’ve learnt a lot while coming to the conclusion.
Should you drop all your work immediately and implement the fake-script method?
Yes and no. If you care about having the highest performance, yes, definitely.
There is absolutely no downside and changing the implementation is not so complex.
However, as always for web-performance related topics, there might be other lower-hanging-fruits, or more impactful things to optimize (maybe you should break up with SVG-in-JS). So before you jump right into optimizing, keep in mind, the state transfer might not be your biggest culprit (e.g. maybe your data is smaller than 60 kB). Measure, then optimize.
Footnotes & Comments
First, thanks to Henrik Joretag - without him, this blog post would have never existed. Additionally, thanks to Anthony Ricaud and Julien Wajsberg, both supported this blog post by brainstorming with me in the WebPerf slack. Last but not least, thanks to Ivan Akulov and Mathias Bynens for the invaluable feedback for this post.
Footnotes
-
The sentence is directly quoted from Barry Pollard; see also https://developer.chrome.com/blog/lighthouse-10-0/#scoring-changes and the web.dev article on TTI ↩
-
While the “invalid mime” approach does not need double escaping to work (
\->\\), you still need to escape the output so that closing-tags (“end-tag open delimiter”) inside strings don’t introduce an XSS vulnerability. The same goes for prototype pollution, which you should prevent before creating the string withJSON.stringify. jsesc handles all of that for you. ↩ ↩2